


windows跑Stable Diffusion喜欢折腾的可以去Github下源码,自己装cuda,cudnn以及python环境,这里就不用这么繁琐的方式了,直接用秋叶大佬打包的工具,傻瓜式喂饭到你嘴里,下载链接我扔到文章最后。
下载sd-webui-aki时如果网速不快,网盘中的controlNet所用的pth模型可以先不下,后面按需要在下,下载完解压如下:

双击启动器运行依赖exe文件,会安装所需环境,有.net,python和cuda,cudnn之类的,不用管直接全部装好。
进入sd-webui-aki-v4.1/sd-webui-aki-v4.1下的运行A启动器.exe,就出现UI界面了,然后点击一键启动,等几秒钟就会弹出网页了:
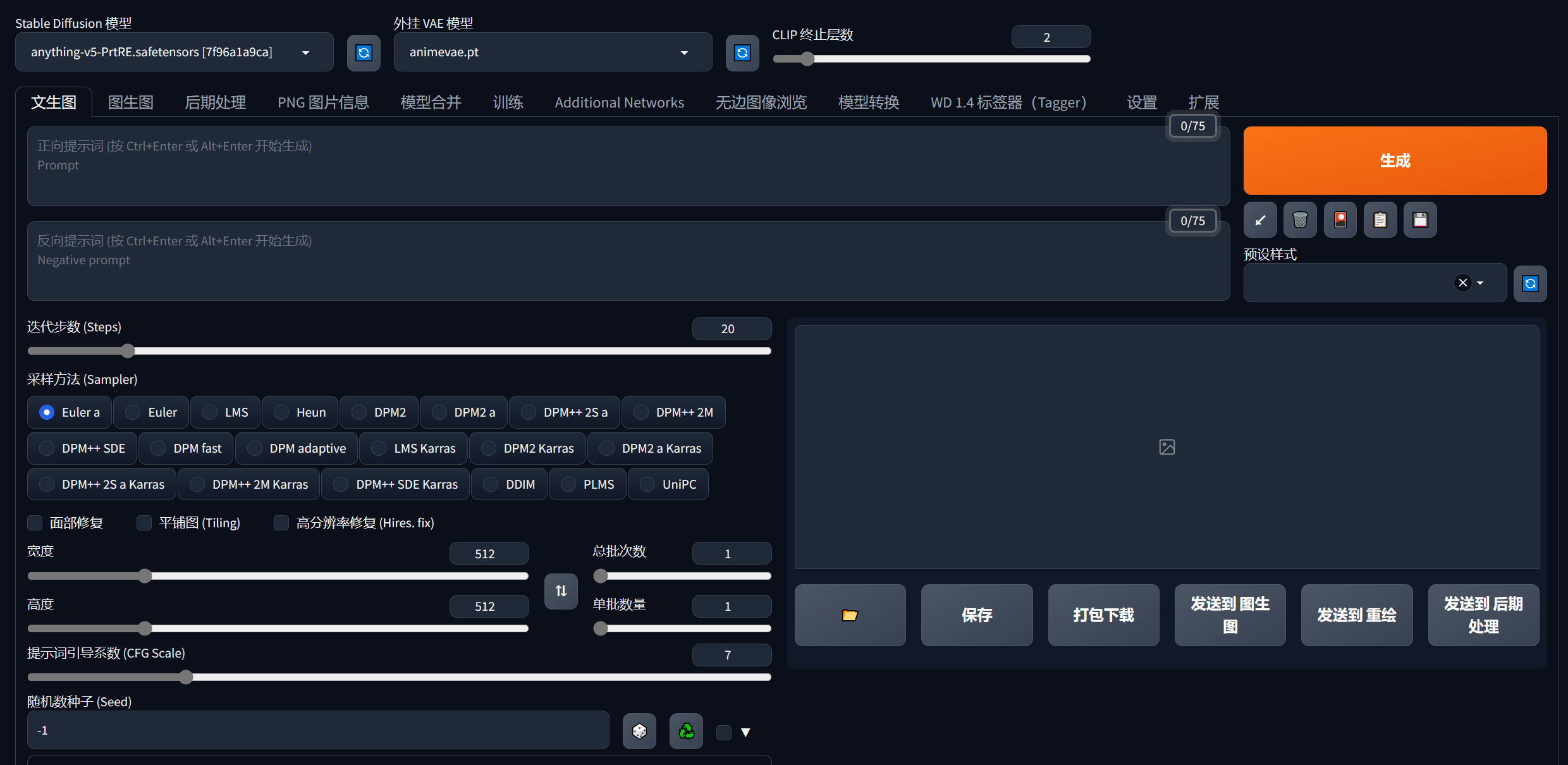
现在就可以直接用了,说一下简单的几个必要设置:
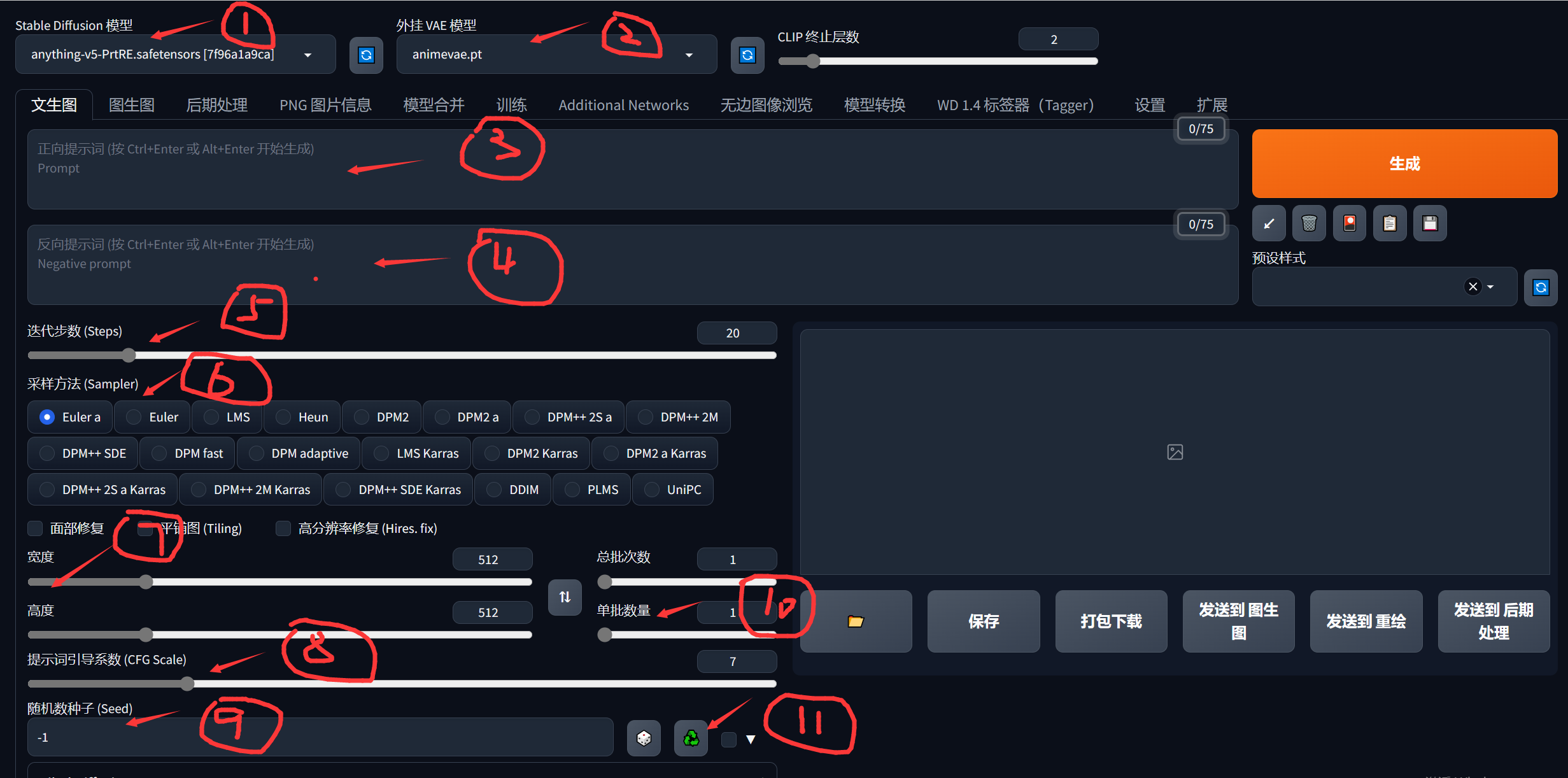
①②这两个是AI的模型,是生成图片的类型和风格最主要的因素,这个不会训练的话,直接用别人训练好的就行了,找模型下面两个网站的最好用:
如果打不开就需要科学上网,推荐第二个,图片的样子可以看到很直观,点进去下载模型即可,Stable Diffusion模型扔在sd-webui-aki-v4.1\sd-webui-aki-v4.1\models\Stable-diffusion文件夹下,Vae模型扔在sd-webui-aki-v4.1\sd-webui-aki-v4.1\models\VAE文件夹下。
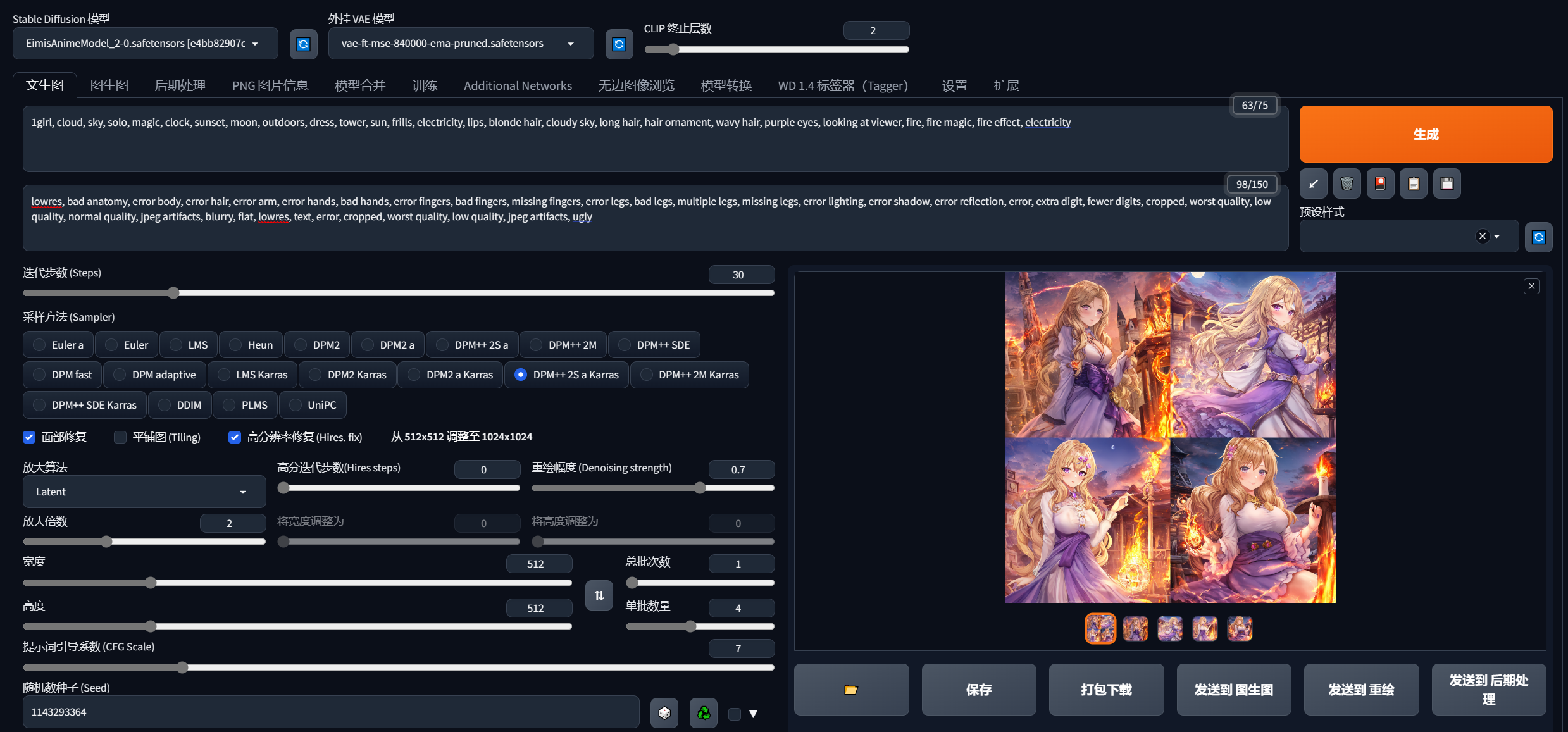
③是正向提示词,就是你想画一张什么样的图,你要用一些英语词汇描述出来,比如lolita,1 girl,big eyes。
④是反向提示词,就是你不想出现的一些东西,比如不想出现蓝色,矮子,就可以写blue,short。(③④这两种提示词很重要,还有些权重写法建议参考网上资料)
⑤这个迭代步数就是图片慢慢像你描述的词汇靠拢的步骤次数,过大了也没啥用,而且会增大你生成时间,一般20-30就够了。
⑥采样方法这个比较复杂,有兴趣去网上看看资料。我一般选择DPM++系列的,DPM++ 2S a Karras最常用,当然你也可以每个都试试,生成图的效果也不一定的。
⑦生成图片的宽高,设置太大会增加生成时间,而且显存不大还可能会爆显存,我拉满用4090都慢的一批。
⑧提示词系数会影响图片的失真和模糊,建议7-10这个区间。
⑨这个随机数种子是保证能拿到一样的图片,比如你随机数给200,其他配置不别,你下次用一样的配置随机数也是填200就可以生成一样的图片,如果你默认为-1,他每次生成图片都会随机。
⑩这个就是你一次生成几张图片,显卡不是太好调小一点,一次一张就行了,太大会很慢甚至可能爆显存。
⑪这个就是获取你当前生成图片的随机数,比如你之前默认为-1,但是你又想下次生成一样的,你就要知道这个随机数是多少,点击一下它,出现的就是当前生成图片的随机数。
 最后上点效果图,还行:
最后上点效果图,还行: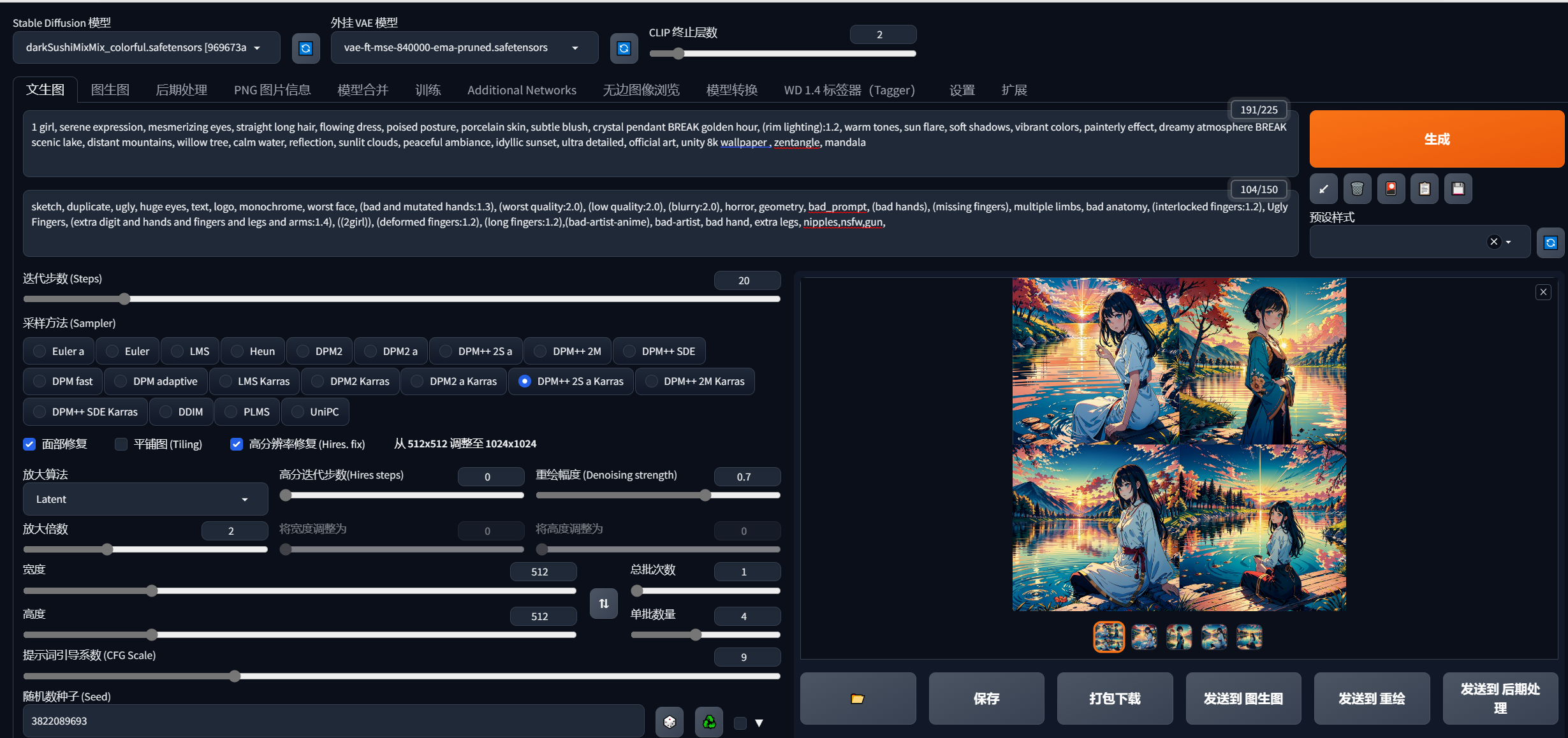
基本配置就这些,更多资料请看秋叶大佬视频:
【AI绘画】Stable Diffusion整合包v4发布!全新加速 解压即用 防爆显存 三分钟入门AI绘画 ☆可更新 ☆训练 ☆汉化_哔哩哔哩_bilibili
以及鱼摆摆喂大佬视频:
你真的会用SD吗?超全面Stable Diffusion基础操作,半小时上手webui!!!_哔哩哔哩_bilibili
Stable Diffusion整合包下载地址如下,提取码 b145:
